The Normalized Cross Correlation Coefficient¶
In this section we summarize some basic properties of the normalized cross correlation coefficient (NCC). This will be useful for the quantification of image similarity and for statistical tests of signifance based the observed values of the NCC.
[1]:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import numpy.ma as ma
from scipy.stats import norm
from scipy.optimize import curve_fit
from scipy.integrate import trapz, simps
from skimage.io import imread
from aloe.plots import plot_image
from PIL import Image
# for fitting probability densities to a normal distribution
def gauss(x,a,x0,sigma):
"""
gaussian function for input x values
with amplitude=a, mean=x0, stddev=sigma
"""
return a*np.exp(-(x-x0)**2/(2*sigma**2))
# seed the random number generator so the randomness below is repeatable
np.random.seed(17139)
Definition¶
A description of various useful interpretations of the correlation coefficient is given by Rodgers and Nicewander in “Thirteeen Ways to Look at the Correlation Coefficent”. An extensive treatment of the statistical use of correlation coefficients is given in D.C. Howell, “Statistical Methods for Psychology”.
The Pearson Correlation Coefficient, or normalized cross correlation coeffcient (NCC) is defined as:
\(r =\frac{\sum ^n _{i=1}(x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum ^n _{i=1}(x_i - \bar{x})^2} \sqrt{\sum ^n _{i=1}(y_i - \bar{y})^2}}\)
This can also be written as:
\(r = r_{xy} = \sum ^n _{i=1} \frac{1}{\sqrt{n-1}} \left( \frac{x_i - \bar{x}}{s_x} \right) \cdot \frac{1}{\sqrt{n-1}} \left( \frac{y_i - \bar{y}}{s_y} \right)\)
sample mean: \(\bar{x}=\frac{1}{n}\sum_{i=1}^n x_i\)
The normalization to \((n-1)\) degrees of freedom in the alternative form of \(r\) above is related to a corresponding definition of the sample standard deviation \(s\): \(s_x=\sqrt{\frac{1}{n-1}\sum_{i=1}^n(x_i-\bar{x})^2}\)
Notes:
- The numerical calculation of the standard deviation in Numpy can use \(n-0\) or \(n-1\), which is controlled by the parameter ddof=0/1. https://docs.scipy.org/doc/numpy/reference/generated/numpy.std.html The average squared deviation is normally calculated as x.sum() / N, where N = len(x). If, however, ddof is specified, the divisor N - ddof is used instead.
- To check the correct implementation, the NCC of a sample with itself needs to return 1.0
[2]:
def norm_data(data):
"""
normalize data to have mean=0 and standard_deviation=1
"""
mean_data=np.mean(data)
std_data=np.std(data, ddof=1)
#return (data-mean_data)/(std_data*np.sqrt(data.size-1))
return (data-mean_data)/(std_data)
def ncc(data0, data1):
"""
normalized cross-correlation coefficient between two data sets
Parameters
----------
data0, data1 : numpy arrays of same size
"""
return (1.0/(data0.size-1)) * np.sum(norm_data(data0)*norm_data(data1))
Simple Example¶
We will use U and V as the names for the random variables in this initial example (to avoid confusion with x and y in a two-dimensional plot, i.e. U and V are both independent variables or observations).
Initialize Some Random Data¶
[3]:
ndata=50
U_true= 3 *(-1.0 + 2.0*np.random.rand(ndata)) # vary between -3 and 3
print('U_true:')
print(U_true)
V_true=2.8*U_true+9.2 # V depends linearly on the *random* U
print('V_true:')
print(V_true)
fig = plt.figure()
ax = fig.add_subplot(111, aspect='equal')
ax.plot(U_true, label='U')
ax.plot(V_true, label='V')
ax.legend(loc='upper left', shadow=True, fancybox=True)
ax.set_ylabel('data values')
ax.set_xlabel('observations')
plt.show()
U_true:
[-2.48878401 -0.13364715 1.39470182 -2.85237912 0.38434844 1.28474665
-0.28210026 -1.33874788 0.44022736 2.10698153 -2.16631113 -0.51309775
2.23026637 2.45915207 -1.67981306 1.50222604 -2.84405916 1.09486124
0.43667326 -2.1551639 -0.78956172 2.28637227 2.05495757 -0.38035358
-2.35889753 0.24364416 -2.15194566 2.44176342 -2.58892038 2.11739048
-1.54875215 -2.48611461 -0.55459832 -2.74094723 1.82820669 -0.25800181
-2.86068972 2.68440632 -1.94363372 0.59279678 1.42118888 -0.03309715
-1.68236838 2.64292534 1.73635566 1.1210353 2.87912719 -1.01469519
2.72985889 -0.68166506]
V_true:
[ 2.23140478 8.82578798 13.10516508 1.21333847 10.27617563 12.79729062
8.41011928 5.45150593 10.43263662 15.09954829 3.13432885 7.76332631
15.44474585 16.0856258 4.49652344 13.40623291 1.23663435 12.26561147
10.42268513 3.16554107 6.98922719 15.60184237 14.9538812 8.13500998
2.59508692 9.88220364 3.17455214 16.03693757 1.95102293 15.12869333
4.86349399 2.2388791 7.64712469 1.52534776 14.31897873 8.47759492
1.19006878 16.71633769 3.75782558 10.85983099 13.17932886 9.10732798
4.48936852 16.60019095 14.06179585 12.33889883 17.26155614 6.35885346
16.8436049 7.29133783]
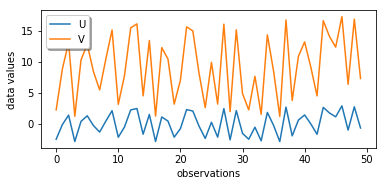
Although each of the line plots by itself looks rather random, when we compare U and V, we see that V is rising when U is rising and V is falling when U is falling, just with a different amplitude and with an underlying offset. A high/low value in the U data set correlates with a high/low value in the V data set.
Correlation Plot¶
To see the relationship between U and V, we plot U as a function of V. Note the use of a scatter plot instead of a line plot; we just like to see the relationship between the related data points.
[4]:
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(U_true,V_true, label= "V vs. U, perfectly correlated")
ax.legend(loc='upper right', shadow=True, fancybox=True)
ax.set_ylabel('V values')
ax.set_xlabel('U values')
ax.set_title('linear correlation between U and V random variables')
plt.show()
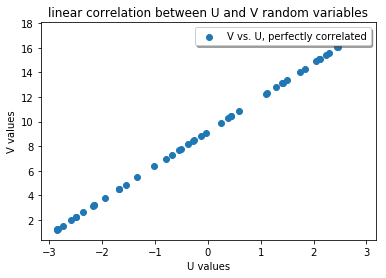
The NCC is 1.0 for these two data sets, indicating that apart from scaling and offset, they are “similar”. Note that the NCC is symmetric, i.e. exchanging the data sets does not change the NCC:
[5]:
ncc1=ncc(U_true,V_true)
print(ncc1)
ncc1_rev=ncc(V_true,U_true)
print(ncc1_rev)
0.9999999999999999
0.9999999999999999
Now we add additional random variations on both U and V and see how the NCC changes.
[6]:
stddev=3.0
U_exp = U_true + np.random.normal(scale=stddev,size=ndata)
V_exp = V_true + np.random.normal(scale=stddev,size=ndata)
fig = plt.figure()
ax = fig.add_subplot(111, aspect='equal')
ax.plot(U_exp, label='U+random')
ax.plot(V_exp, label='V+random')
ax.legend(loc='upper right', shadow=True, fancybox=True)
ax.set_ylabel('data values')
ax.set_xlabel('observations')
plt.show()
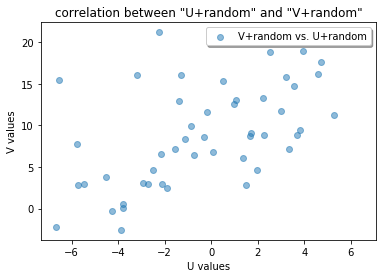
Now we check the correlation between the U and V data with random errors, and we see that we don not have a nice line anymore!
[7]:
ncc2=ncc(U_exp,V_exp)
print(ncc2)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(U_exp,V_exp, alpha=0.5, label= "V+random vs. U+random")
ax.legend(loc='upper right', shadow=True, fancybox=True)
ax.set_ylabel('V values')
ax.set_xlabel('U values')
ax.set_title('correlation between "U+random" and "V+random"')
plt.show()
0.5843524495386023
Statistical Distribution of the Cross Correlation Coefficient¶
We now compare the distribution of the NCC values for a large set of experiments (y) with the theory (x). So x and y correspond to U and V in the simple example above.
We can start by looking at the result of totally random data in x and y, where the different NCCs should be distributed around zero.
Note: Try to set the “stddev” value below to different values and observe what happens if x and y become increasingly spread. The surprising result is that the spread of the NCC histogram does not change with the standard deviation of the distribution of the actual values in the x and y data sets! Then what determines the shape of this curve? The answer will follow below…
[8]:
def get_correlated_samples(nsamples=50, r=0.5, means=[1,1], stddevs= [1.0, 1.0]):
"""
get two correlated random data sets
"""
sd = np.diag(stddevs) # SD in a diagonal matrix
observations = np.random.normal(0, 1, (2, nsamples))
cor_matrix = np.array([[1.0, r],
[r, 1.0]]) # correlation matrix [2 x 2]
cov_matrix = np.dot(sd, np.dot(cor_matrix, sd)) # covariance matrix
Chol = np.linalg.cholesky(cov_matrix) # Cholesky decomposition
sam_eq_mean = Chol.dot(observations) # Generating random MVN (0, cov_matrix)
s = sam_eq_mean.transpose() + means # adding the means column wise
samples = s.transpose() # Transposing back
return samples
def get_r_sample(nruns=1000, nsamples=50, r=0.5,
means=[0, 0], stddevs=[1.0, 1.0]):
""" get correlated x,y datasets with defined correlation r """
samples=np.zeros(nruns)
for i in range(nruns):
x,y = get_correlated_samples(nsamples=nsamples, r=r,
means=means, stddevs=stddevs)
samples[i]=ncc(x,y)
return samples
def get_ncc_sample_r0(nruns=1000,stddev=1.0):
"""
get ncc samples from population with correlation=0
"""
samples=np.zeros(nruns)
for i in range(nruns):
x = np.random.normal(scale=stddev,size=ndata)
y = np.random.normal(scale=stddev,size=ndata)
samples[i]=ncc(x,y)
return samples
We will first plot a histogram for a range of trials where we create two datasets of ndata points and calculate their NCC. The NCC will not be constant, as our data sets are random. The NCC can be different from zero in the specific trials, as we can have accidentally correlated values for a dataset of limited size, i.e. there is some chance for three random values to be correlated with NCC=0.1 to three other random values. We expect that the variation of the NCC values around zero will become sharper for larger data sets, i.e. there is a much smaller chance for 100 random values to show NCC=0.1 to 100 other random values.
[9]:
nruns=10000
stddev=37.0
ncc_samples=np.zeros(nruns)
for i in range(nruns):
x = np.random.normal(scale=stddev,size=ndata)
y = np.random.normal(scale=stddev,size=ndata)
ncc_samples[i]=ncc(x,y)
counts, binval, _ = plt.hist(ncc_samples,bins=51)
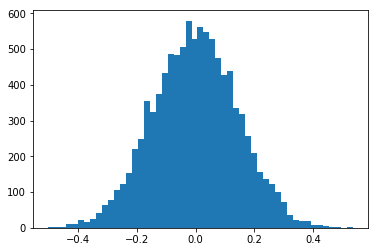
Now we compare experiments for the same underlying true x and y data (taken from the U and V data sets above), however with two different amounts of randomness in the experimental x and y. Because of the correlation between x and y, the NCC distribution is centered around a nonzero value and the distribution histogram of the NCC becomes asymmetric relative to the most probable NCC value.
First, we add Gaussian noise with stddev=10.0 to the true, perfectly correlated values, and the NCC values will decrease any vary asymmetrically around about 0.4:
[10]:
nruns=10000
stddev=10.0
x_true = U_true
y_true = V_true
ncc_samples=np.zeros(nruns)
for i in range(nruns):
x = x_true
y = y_true + np.random.normal(scale=stddev,size=ndata)
ncc_samples[i]=ncc(x,y)
counts, binval, _= plt.hist(ncc_samples,bins=51)
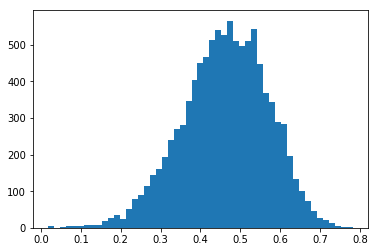
With less random noise (stddev=2.0) on the true, perfectly correlated values, the most probable NCC moves nearer to 1.0:
[11]:
nruns=10000
stddev=2.0
ncc_samples=np.zeros(nruns)
for i in range(nruns):
x2 = x_true
y2 = y_true + np.random.normal(scale=stddev,size=ndata)
ncc_samples[i]=ncc(x2,y2)
counts, binval, _= plt.hist(ncc_samples,bins=51)
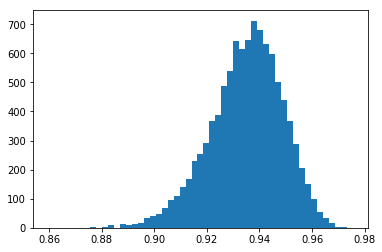
With even less noise, stddev=0.2, the NCC values approach 1.0. Note that the NCC still varies, but it can never be larger than 1.0.
[12]:
nruns=10000
stddev=0.2
ncc_samples=np.zeros(nruns)
for i in range(nruns):
x2 = x_true
y2 = y_true + np.random.normal(scale=stddev,size=ndata)
ncc_samples[i]=ncc(x2,y2)
counts, binval, _= plt.hist(ncc_samples,bins=51)
Degrees Of Freedom:¶
We check what happens to the distribution of NCC values when we repeat some values in the x and y data sets.
[13]:
nruns=10000
stddev=50.0
# sample size 5 times of original data, all random
# ~ 5 times more dof
ncc_samples=np.zeros(nruns)
for i in range(nruns):
x = np.random.normal(scale=stddev,size=5*ndata)
y = np.random.normal(scale=stddev,size=5*ndata)
ncc_samples[i]=ncc(x,y)
# repeat 5 samples of ndata
ncc_samples5=np.zeros(nruns)
for i in range(nruns):
x = np.random.normal(scale=stddev,size=ndata)
y = np.random.normal(scale=stddev,size=ndata)
x=np.ravel([x,x,x,x,x])
y=np.ravel([y,y,y,y,y])
ncc_samples5[i]=ncc(x,y)
# compare to result for original sample size/dof
ncc_samples1=np.zeros(nruns)
for i in range(nruns):
x = np.random.normal(scale=stddev,size=ndata)
y = np.random.normal(scale=stddev,size=ndata)
ncc_samples1[i]=ncc(x,y)
[14]:
fig = plt.figure()
plt.subplots_adjust(hspace = 1.1)
ax = fig.add_subplot(311)
counts, binval, _ = plt.hist(ncc_samples,bins=51)
ax.set_xlim(-0.5,0.5)
ax.set_xlabel('NCC, size 5x ndata, random')
ax = fig.add_subplot(312)
counts, binval, _ = plt.hist(ncc_samples5,bins=51)
ax.set_xlim(-0.5,0.5)
ax.set_xlabel('NCC, size 5x ndata, 5x repeat same ndata')
ax = fig.add_subplot(313)
counts, binval, _ = plt.hist(ncc_samples1,bins=51)
ax.set_xlim(-0.5,0.5)
ax.set_xlabel('NCC ndata')
plt.show()

The variation of ncc_samples5 (middle) is the same as that of the initial set with size ndata (bottom), while a data set with \(5\times\)ndata truly random data points shows a reduced variation in the distribution of the NCC values. We cannot reduce the variation of the NCC by simply repeating some values.
Since in our data set of \(5\times\) repeated ndata samples, not all observations are independent, the sample size in this case is NOT equivalent to the degrees of freedom in the data set. From the plots above, we would expect that, compared to \(5\times\) ndata, the effective sample size should be ndata, as this gives the same distribution as our \(5\times\) repeated ndata points.
The correlation in the \(5\times\) repeated ndata points reduces the effective sample size, which is signaled by the increased width of the NCC curve around zero, compared to \(5\times\)ndata independent random values.
Will this observation enable us to define at least an effective sample size (DOF) via the distribution of the NCC? (WIP)
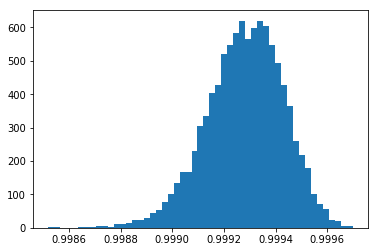
Standard Deviation and Degrees Of Freedom for Zero Correlation¶
Fit to Model for NCC distribution around \(r=0\):
[15]:
ncc0=get_ncc_sample_r0(nruns=10000, stddev=0.7)
[16]:
ax = plt.subplot(111)
counts, binval, patches = plt.hist(ncc0,bins=100, density=True)
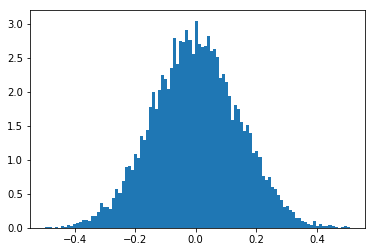
[17]:
zmean,zstd=norm.fit(ncc0)
print(zmean,zstd)
dof0=2+(1.0/zstd)*(1.0/zstd)
print(dof0)
print(ndata)
print('?!')
1.3458304497317376e-05 0.14160349116255136
51.87145953120684
50
?!
[18]:
plt.hist(ncc0, bins=100, density=True)
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
y = norm.pdf(x, zmean, zstd)
plt.plot(x, y)
plt.show()
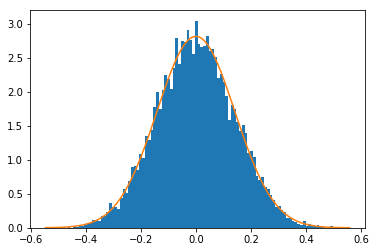
For uncorrelated data sets (mean value of NCC is 0), we can extract the initial degrees of freedom (the independent data points \(N\)) from the standard deviation \(\sigma\) of a normal distribution fitted to the histogram of the NCC values (see Howell):
\(\sigma_r= \frac{ 1 }{ \sqrt{N-2} }\)
Given only the histogram above, we can estimate the ndata=50 defined for the random data sets at the beginning of this chapter. In addition, note that this result does not depend on the standard deviation or mean of the uncorrelated data sets, which seems a little like magic, doesn’t it?
Can we also achieve something similar when the data is correlated, i.e. the mean NCC is \(r>0\)? It turns out that this is possible after transforming the NCC \(r\) values so that they become distributed normally also for \(r>0\), as will be discussed next.
Z transformation¶
Fisher (1921) has shown that one can convert the NCC \(r\) to a value \(z\) that is approximately normal distributed (see Howell, Chapter 9, “Correlation and Regression”). The calculation of \(z\) will enable us to compare the variation of the NCC at different levels of the NCC, e.g. we can answer questions like “Is the correlation between two data sets significantly different from the correlation between a second pair of data sets” (where the data sets can have a different number of observations etc and thus a different statistical variation of the NCC values).
\(z= 0.5\cdot\ln\frac{|1+r|}{|1-r|}\)
[19]:
def z_transform(r):
"""
Fisher's z transform for the correlation coefficient
"""
return 0.5*np.log((1.0+r)/(1.0-r))
[20]:
ncc1 = get_r_sample(nruns=10000, r=0.9, stddevs=[0.1,200])
z1=z_transform(ncc1)
ncc2 = get_r_sample(nruns=10000, r=0.2, stddevs=[3,17])
z2=z_transform(ncc2)
[21]:
fig = plt.figure()
plt.subplots_adjust(hspace = 0.6)
ax = fig.add_subplot(221)
counts, binval, _= ax.hist(ncc1,bins=51, density=False)
#ax.set_xlim(-0.5,0.8)
ax.set_xlabel('NCC 1')
ax = fig.add_subplot(222)
counts, binval, _= ax.hist(ncc2,bins=51, density=False)
#ax.set_xlim(-0.5,0.8)
ax.set_xlabel('NCC 2')
ax = fig.add_subplot(223)
counts, binval, _= ax.hist(z1,bins=51, density=False)
#ax.set_xlim(0.49,0.8)
ax.set_xlabel('z 1')
ax = fig.add_subplot(224)
counts, binval, _= ax.hist(z2,bins=51, density=False)
#ax.set_xlim(0.49,0.8)
ax.set_xlabel('z 2')
plt.show()
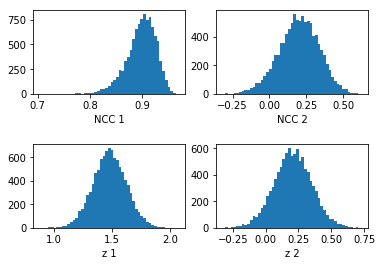
Note, in the plots above, the noise can be different between upper and lower rows because of the different binning of the NCC \(r\) values vs. \(z\)-transformed values.
Estimation of DOF from correlated data¶
The Degrees Of Freedom \(N\) for non-zero correlation can be estimated from the standard deviation of the z-transformed NCC values. For correlated data sets (mean value of NCC <> 0), \(z\) is approximately normally distributed with standard error \(\sigma_z\) (see Howell, Chapter 9, “Correlation and Regression”):
\(\sigma_z= \frac{ 1 }{ \sqrt{N-3} }\)
Like in the case of zero correlation, we can try to recover the initial Degrees of Freedom from the standard deviation of \(z\) as:
\(N=\frac{1}{\sigma_z^2}+3\)
[22]:
def get_DOF_from_zstd(zstd):
return 3+(1.0/zstd)**2
zmean1,zstd1=norm.fit(z1)
print('z1 mean, std:', zmean1,zstd1)
dof1=get_DOF_from_zstd(zstd1)
print('DOF1 from sigma:', dof1)
zmean2,zstd2=norm.fit(z2)
print('z2 mean, std:', zmean2,zstd2)
dof2=get_DOF_from_zstd(zstd2)
print('DOF2 from sigma:', dof2)
z1 mean, std: 1.4800939597596763 0.14494532687212142
DOF1 from sigma: 50.598313381070234
z2 mean, std: 0.20615464743747453 0.14421090214204885
DOF2 from sigma: 51.084356972551404
For our independent random data points with defined correlation , we nicely obtain values near 50, the initial ndata, for arbitrary mean and standard deviation in the two data sets! Statistical magic again…
[23]:
fig=plt.figure()
plt.subplots_adjust(hspace = 0.6)
ax = fig.add_subplot(211)
ax.hist(z1, bins=100, density=True)
xmin, xmax = ax.get_xlim()
x = np.linspace(xmin, xmax, 100)
y = norm.pdf(x, zmean1, zstd1)
ax.plot(x, y)
ax.set_xlabel('$z_1$')
ax.set_xlim([-0.3, 2.1])
ax = fig.add_subplot(212)
ax.hist(z2, bins=100, density=True)
xmin, xmax = ax.get_xlim()
x = np.linspace(xmin, xmax, 100)
y = norm.pdf(x, zmean2, zstd2)
ax.plot(x, y)
ax.set_xlabel('$z_2$')
ax.set_xlim([-0.3, 2.1])
plt.show()
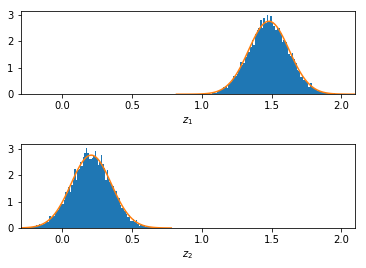
In the two plots above, we can see that the \(z\)-transformation nicely scales the distributions to have the same standard deviation (which is determined by the DOF), even with strongly different values of the correlation coefficients. As the standard deviations are the same, we obtain the same estimate for ndata.
Example Data: Kikuchi Pattern Fits¶
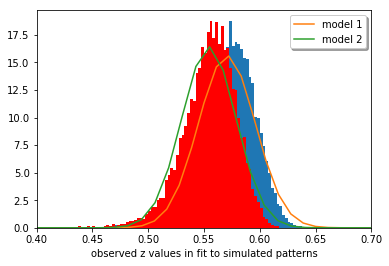
We now look at an example for the distribution of the values of the NCC for a range of different “experiments”. An “experiment” will correspond to the intensity values in an image that was flattened to a 1D array. The example data is from an EBSD measurement for a large number (16752) of different Kikuchi patterns (200x142 = 28400 pixels = length of 1D array data set like in U or V above). The aim was to discriminate between two different possible “theories”, which show a slightly different NCC when compared to a single experimental pattern.
For the 16752 pattern fits, a different NCC value is obtained relative to both theories (\(r_0\), \(r_1\)), and we have to decide which of the two theories is the better fit and possibly give a confidence level for this discrimination.
[24]:
mtxt=np.loadtxt(fname='./data/K2C_0802_200x142.MTXT',skiprows=1)
print(mtxt.shape)
(16752, 17)
[25]:
r0=mtxt[:,15]
r1=mtxt[:,16]
z0=z_transform(r0)
z1=z_transform(r1)
#save
zxc0=z0
zxc1=z1
[26]:
zmean0,zstd0=norm.fit(z0)
print(zmean0,zstd0)
dof0=get_DOF_from_zstd(zstd0)
print(dof0)
zmean1,zstd1=norm.fit(z1)
print(zmean1,zstd1)
dof1=get_DOF_from_zstd(zstd1)
print(dof1)
0.5704894030485244 0.02553383706134989
1536.796825594422
0.5544172786435242 0.024283068143748792
1698.8712701227655
[27]:
counts0, bin_edges0, bars0 = plt.hist(z0, bins=400,
range=[0.0, 1.0], density=True)
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
y = norm.pdf(x, zmean0, zstd0)
plt.plot(x, y, label = 'model 1')
counts1, bin_edges1, bars1 = plt.hist(z1, bins=400,
range=[0.0, 1.0], density=True,color='r')
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
y = norm.pdf(x, zmean1, zstd1)
plt.plot(x, y, label = 'model 2')
plt.xlim(0.4,0.7)
plt.xlabel('observed z values in fit to simulated patterns')
plt.legend(loc='upper right', shadow=True, fancybox=True)
plt.show()
Alternative description of the statistical distribution: Gaussian peak fitting
Instead of using the mean and standard deviation as estimators, we can also use a peak fit to the distribution of NCC values.
[28]:
z1= 0.5*(bin_edges1[1:] + bin_edges1[:-1])
print('area under curve: ',trapz(counts1, z1))
popt,pcov = curve_fit(gauss,z1,counts1,p0=[np.max(counts1),np.mean(z1),1.0])
a_fit, mean_fit, sigma_fit = popt
print(a_fit, mean_fit, sigma_fit)
dofdz=get_DOF_from_zstd(sigma_fit)
print('DOF: ',dofdz)
plt.scatter(z1,counts1,label='$z_1$',color='b')
plt.plot(z1,gauss(z1,*popt),'b',label='fit $z_1$')
z0= 0.5*(bin_edges0[1:] + bin_edges0[:-1])
print('area under curve: ',trapz(counts0, z0))
popt,pcov = curve_fit(gauss,z0,counts0,p0=[np.max(counts0),np.mean(z0),1.0])
a_fit, mean_fit, sigma_fit = popt
print(a_fit, mean_fit, sigma_fit)
dofdz=3+(1.0/sigma_fit)**2
print('DOF: ',dofdz)
plt.scatter(z0,counts0,label='$z_0$',color='r')
plt.plot(z1,gauss(z0,*popt),'r',label='fit $z_0$')
#plt.xlim(0.75,0.87)
plt.xlim(0.4,0.7)
plt.legend()
plt.show()
area under curve: 1.0000000000000002
17.93916300442126 0.5579065730213564 -0.021820875063898286
DOF: 2103.175919211425
area under curve: 1.0000000000000002
17.003931263802883 0.5741550518076884 -0.02305540709794952
DOF: 1884.2842072483918
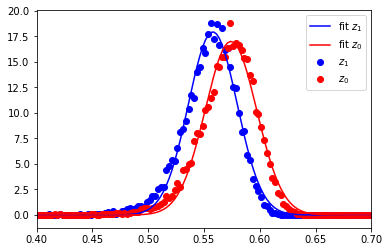
From the standard deviation of the distribution of the NCC values, we would naively estimate the effective DOF to be in the range of 2000 for the patterns of 200x142=28400 pixels.
In a test scenario, we could assume the null hypothesis that both NCCs are equal, and thus test for the difference to be zero.
The overlap of the curves does not mean that we actually have data points (patterns) where the difference in \(z\) is zero. This is because the values in both curves are strongly correlated, i.e. if we have a value in the high end of the tail of th \(z_0\) curve, the corresponding \(z_1\) value will be in the high end tail of the \(z_1\) curve, i.e. not in the low end which would be required to make the difference \(z_1 - z_0\) zero.
To see the correlation effect, we additionally analyze the distribution of the differences of the z-transformed r values:
[29]:
dz=np.abs(zxc1-zxc0)
counts, bin_edges, bars = plt.hist(dz, bins=500, range=[0.0, 0.1],
density=True, color='y',label='$\Delta z$')
z = 0.5*(bin_edges[1:] + bin_edges[:-1])
zc=counts
print('area under curve: ',trapz(zc, z))
popt,pcov = curve_fit(gauss,z,zc,p0=[np.max(zc),np.mean(z),1.0])
a_fit, mean_fit, sigma_fit = popt
print(a_fit, mean_fit, np.abs(sigma_fit))
dofdz=3+(1.0/(np.sqrt(2)*sigma_fit))**2
print('DOF: ',dofdz)
#plt.scatter(z,zc,label='$\Delta z$', color='y')
plt.plot(z,gauss(z,*popt),'k',label='Gaussian fit',
lw=3.0, alpha=0.95)
plt.xlim(0.0,0.06)
plt.legend()
plt.show()
area under curve: 0.9999999999999999
152.89324508417772 0.01616606770568351 0.0025878698651480166
DOF: 74662.51038720872
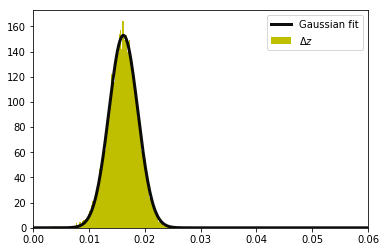
The estimated DOF from the z difference is unrealistically too large because the two distributions from which the z difference was obtained are not independent. Thus we cannot simply apply \(\sigma_{diff}^2 = \sigma_0^2 + \sigma_1^2 = 2\sigma_m^2\) to estimate the mean sigma \(\sigma_m\) of the initial from the distribution of the differences \(\sigma_{diff}\). The sigma of the z difference is much smaller than expected for independent random \(z_0\) and \(z_1\).
If we assume that the fitted plot above is the true frequency distribution, clearly all or almost all experimentally observed values are away from 0.0, which would allow us to reject the null hypothesis at the 99.9…% level.
The problem is that we do not know the theoretical distribution beforehand, because our data points (image pixel intensities) are not independent and we do not know the “effective DOF” in a specific Kikuchi pattern. Otherwise we can estimate the theoretical distribution of the NCC values and also their difference from the DOF, like shown above. Once an estimation for the effective DOF in a Kikuchi pattern is avalaible, the usual testing scenarios are straightforward.
Since we compare the same experimental pattern with two theories that are also correlated, the change in NCC between the two comparison is smaller than would be expected for two independent theoretical patterns (i.e. the two theoretical patterns look very similar also).
To be mathematically correct, the “spatial” correlation between the image pixels, as well as the mutual correlation of the simulated theory-patterns need to be included somehow in the test scenario. We can know the correlation between the theoretical patterns, but we also have to estimate the spatial correlation in each of the theoretical patterns. (Hoteling, Schneider, see D.C. Howell, “Statistical Methods for Psychology”).
Application as an Image Similarity Measure¶
The NCC (a.k.a. Pearson correlation coefficient, \(r\)) has several useful properties for the quantitative comparison of EBSD patterns.
- normalized patterns on well defined scale (mean=0.0 and standard deviation=1.0)
- inversion of contrast is trivial: multiply the normalized pattern by -1
A number of similarity and dissimilarity measures for images are discussed, for example, in A. Goshtasby “Image Registration” (Springer, 2012), who summarizes the question of choosing a similarity/dissimilarity measure for photographic images (p.57):
Each similarity/dissimilarity measure has its strengths and weaknesses. A measure that performs well on one type of images may perform poorly on another type of images. Therefore, an absolute conclusion cannot be reached about the superiority of one measure against another. However, the experimental results obtained on various image types and various image differences reveal that Pearson correlation coefficient, Tanimoto measure, minimum ratio, L\(_1\) norm, square L\(_2\) norm, and intensity ratio variance overall perform better than other measures. If the images are captured under different exposures of a camera or under different lighting of a scene, the results show that Pearson correlation coefficient, Tanimoto measure, normalized square L\(_2\) norm, and incremental sign distance perform better than others.
The Normalized Inner Product (NIP) (also called Normalized Dot Product) which is not discusssed by Gotashby in the reference above, has also been used as a similarity measure for pattern matching and indexing of EBSD and ECP under various experimental conditions and pattern qualities, and including a corresponding NIP-based error analysis of orientation determination and phase discrimination. See for example:
- [1] Y.H. Chen et al., A Dictionary Approach to Electron Backscatter Diffraction Indexing, Microscopy and Microanalysis 21 (2015) 739
- [2] S. Singh, M. De Graef, Dictionary Indexing of Electron Channeling Patterns. Microscopy and Microanalysis 23 (2017) 1
- [3] S. Singh, F. Ram and M. De Graef , Application of forward models to crystal orientation refinement, J. Appl. Cryst. (2017) 50
- [4] F. Ram, S. Wright, S. Singh, and M. De Graef , Error analysis of the crystal orientations obtained by the dictionary approach to EBSD indexing, Ultramicroscopy 181 (2017) 17
- [5] K. Marquardt, M. De Graef, S. Singh, H. Marquardt, A. Rosenthal, S. Koizuimi Quantitative electron backscatter diffraction (EBSD) data analyses using the dictionary indexing (DI) approach: Overcoming indexing difficulties on geological materials American Mineralogist 102 (2017) 1843
- [6] F. Ram and M. De Graef , Phase differentiation by electron backscatter diffraction using the dictionary indexing approach, Acta Materialia 144 (2018) 352
- [7] S. Singh, Y. Guo, B. Winiarski, T. L. Burnett, P. J. Withers, M. De Graef High resolution low kV EBSD of heavily deformed and nanocrystalline Aluminium by dictionary-based indexing Scientific Reports 8 (2018) 10991
In the following, we will demonstrate some key differences between the NCC and the NIP, which is defined according to [1,4] as:
\(\rho =\frac{ \langle \mathbf{X} , \mathbf{Y} \rangle}{||\mathbf{X}|| \cdot ||\mathbf{Y}||}\)
with \({\langle \mathbf{X} , \mathbf{Y} \rangle}\) being the dot product (inner product) of the image vectors \(\mathbf{X}\) and \(\mathbf{Y}\).
Note that, compared to the NCC, the NIP does neither involve the removal of the mean from the image nor does it involve a normalization according to the image “energy” (standard deviation = 1.0). These features will make the NIP much less useful as an image similarity measure when images are compared which vary in intensity and mean level. We will also show the different reaction of the NCC and NIP when comparing experimental data to pure noise, which will show the the NIP is an unreliable predictor of vanishing agreement.
[30]:
def norm_dot(img1, img2):
"""
return normalized dot product of the arrays img1, img2
"""
# make 1D value lists
v1 = np.ravel(img1)
v2 = np.ravel(img2)
# get the norms of the vectors
norm1 = np.linalg.norm(v1)
norm2 = np.linalg.norm(v2)
#print('norms of NDP vectors: ', norm1, norm2)
ndot = np.dot( v1/norm1, v2/norm2)
return ndot
To get a feeling for the typical relative values for a low-noise experimental image and a suffciently good simulation, we compare the NCC and the NIP of two images:
[31]:
def print_similarity_measures(img1, img2, nc0=None, nd0=None):
nd = norm_dot(img1, img2)
nc = ncc(img1, img2)
print('NCC: ', nc, ' NDP: ', nd)
if not ((nc0 is None) or (nd0 is None)):
print('dNCC: ', nc-nc0, ' dNDP: ', nd-nd0)
return
As a first test, we check the similarity of an image with itself, which should result in a value of 1.0 in both cases:
[32]:
img_exp = np.array(Image.open('./data/ocean_grain_final.png').convert(mode='L'), dtype=np.float64)
plot_image(img_exp)
print(img_exp.shape, img_exp.dtype)
print_similarity_measures(img_exp, img_exp)
img_sim = np.array(Image.open('./data/ocean_dynsim.png').convert(mode='L'), dtype=np.float64)
plot_image(img_sim)
print(img_sim.shape, img_sim.dtype)
print_similarity_measures(img_sim, img_sim)
(240, 320) float64
NCC: 0.9999999999999997 NDP: 1.0
(240, 320) float64
NCC: 1.0000000000000002 NDP: 1.0
We now check the similarity between the experimental pattern and the simulated pattern, and obtain a NCC near 0.7, which usually indicates a very good fit; the relevant NIP is 0.966 for the two loaded images:
[33]:
# initial images
test_exp = img_exp
test_sim = img_sim
ndot_0 = norm_dot(test_exp, test_sim)
ncc_0 = ncc(test_exp,test_sim)
print('NCC: ', ncc_0)
print('NIP: ', ndot_0)
NCC: 0.6934039295128853
NIP: 0.966085369229993
[34]:
# scale both: the ncc and ndp stay at their initial values
test_exp = 2.0*img_exp
test_sim = 2.0*img_sim
print_similarity_measures(test_exp, test_sim)
NCC: 0.6934039295128853 NDP: 0.966085369229993
[35]:
# scale both differently: the ncc and ndp stay at their initial values
test_exp = 2.0*img_exp
test_sim = 5.0*img_sim
print_similarity_measures(test_exp, test_sim)
NCC: 0.6934039295128853 NDP: 0.9660853692299929
[36]:
# offset
test_exp = img_exp+100
test_sim = img_sim+100
print_similarity_measures(test_exp, test_sim)
NCC: 0.6934039295128853 NDP: 0.9903671259223557
An offset which is large enough will drive the NDP towards 1.0, because the relative variations in the image vector length due to the image intensity variations will become neglible:
[37]:
test_exp = img_exp+100000
test_sim = img_sim+100000
print_similarity_measures(test_exp, test_sim)
NCC: 0.6934039295128853 NDP: 0.9999999579164437
[38]:
test_exp = img_exp-100
test_sim = img_sim
print_similarity_measures(test_exp, test_sim)
NCC: 0.6934039295128853 NDP: 0.6221259676934416
[39]:
test_exp = img_exp
test_sim = img_sim-1000
print_similarity_measures(test_exp, test_sim)
NCC: 0.6934039295128853 NDP: -0.9477149135723966
[40]:
test_exp = -1.0*img_exp+8000
test_sim = -1.0*img_sim-1000
print_similarity_measures(test_exp, test_sim)
NCC: 0.6934039295128855 NDP: -0.9992710340851816
Comparison of Random Images¶
For checking the behaviour of the image simalrity for totally random images, we create images with uniformly distributed random float values from 0 to 1 and then calculate the NCC and NIP. As a first check, we make sure that the NCC and NIP of random noise with itself is also 1.0:
[41]:
img_random = np.random.rand(img_exp.shape[0], img_exp.shape[1])
plot_image(img_random)
print_similarity_measures(img_random, img_random)

NCC: 0.9999999999999997 NDP: 1.0
We expect that two different random images should be completely dissimilar, which should be reflected in the values of the NCC and NIP, which should be different from 1.0. The calculation for two different random images gives a value near 0.0 for the NCC, which is consistent with our sense of similarity. However, we obtain but a value near 0.75 for the NIP, so this indicates that “complete dissimilarity” is signalled by a value of the NIP near 3/4 (for an explanation, where this value comes from, see below):
[42]:
# random images
img1_random = np.random.rand(img_exp.shape[0], img_exp.shape[1])
img2_random = np.random.rand(img_exp.shape[0], img_exp.shape[1])
plot_image(img1_random)
plot_image(img2_random)
print_similarity_measures(img1_random, img2_random)


NCC: -0.0052766729699176345 NDP: 0.7487770197475101
[43]:
nruns=10000
def compare_random_images(nruns, offset=0.0, scale=1.0):
nc_list=np.zeros(nruns, dtype=np.float32)
nd_list=np.zeros(nruns, dtype=np.float32)
for i in range(nruns):
# 0..1 float random numbers
img1_random = np.random.rand(img_exp.shape[0], img_exp.shape[1])
img2_random = np.random.rand(img_exp.shape[0], img_exp.shape[1])
# note: difference for images 0..1 values as compared -1,1
test_exp = offset + scale * img1_random
test_sim = offset + scale * img2_random
nc_list[i] = ncc(test_exp, test_sim)
nd_list[i] = norm_dot(test_exp, test_sim)
return nc_list, nd_list
nc_vals, nd_vals = compare_random_images(nruns)
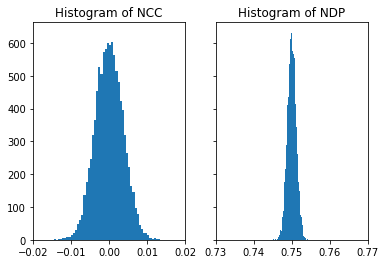
When normalizing each image with 8bit intensities from 0..255 (or 0..65535 for 16bit), the resulting (random) unit image vectors reside only in one quadrant of the high-dimensional sphere so we obtain a value of 3/4 for the expection value of the NDP, not zero like for the NCC.
see, e.g. a discussion here: https://math.stackexchange.com/questions/2422001/expected-dot-product-of-two-random-vectors
[44]:
fig, (ax1, ax2) = plt.subplots(1, 2, sharey=True)
ax1.hist(nc_vals, bins=50)
ax1.set_title('Histogram of NCC')
ax1.set_xlim([-0.02, 0.02])
ax2.hist(nd_vals, bins=50)
ax2.set_title('Histogram of NDP')
ax2.set_xlim([-0.02+0.75, 0.02+0.75])
plt.show()
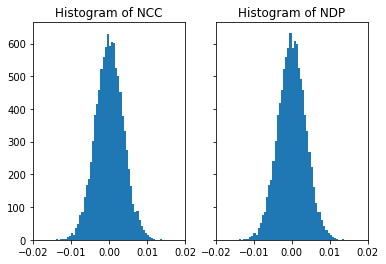
If we use a symmetrical range around 0.0 for the image entries, we effectively calculate the NCC, and thus NDP=NCC in this limit:
[45]:
# this is for vectors with entries -1...1
nc_vals, nd_vals = compare_random_images(nruns, offset=-1.0, scale=2.0)
[46]:
# now we have the same histogram for both (i.e. ncc=ndp in this limit, since we have the mean=0.0)
fig, (ax1, ax2) = plt.subplots(1, 2, sharey=True)
ax1.hist(nc_vals, bins=50)
ax1.set_title('Histogram of NCC')
ax1.set_xlim([-0.02, 0.02])
ax2.hist(nd_vals, bins=50)
ax2.set_title('Histogram of NDP')
ax2.set_xlim([-0.02, 0.02])
plt.show()
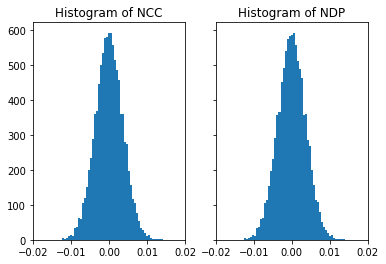
[47]:
# this is for vectors with entries -0.5...0.5
nc_vals, nd_vals = compare_random_images(nruns, offset=-0.5, scale=1.0)
[48]:
fig, (ax1, ax2) = plt.subplots(1, 2, sharey=True)
ax1.hist(nc_vals, bins=50)
ax1.set_title('Histogram of NCC')
ax1.set_xlim([-0.02, 0.02])
ax2.hist(nd_vals, bins=50)
ax2.set_title('Histogram of NDP')
ax2.set_xlim([-0.02, 0.02])
plt.show()
Comparison of Kikuchi Patterns to Random Noise¶
In this section, we will show the different reaction of the NCC and NIP when comparing experimental data to pure noise. Compared to the NCC, the the NIP is an unreliable predictor of vanishing agreement with a test pattern because different Kikuchi patterns show a different NIP distribution when compared to the same type of noise. In contrast, the NCC values are centered around 0.0 for the test patterns when compared to pure noise.
[49]:
img_exp_1 = np.array(Image.open('./data/Si_15000_BAM_320.png').convert(mode='L'), dtype=np.uint8)
img_exp_2 = np.array(Image.open('./data/ocean_grain_final.png').convert(mode='L'), dtype=np.uint8)
img_exp_3 = imread("../data/patterns/Ni_Example3.png")
print(img_exp_1.shape, img_exp_1.dtype)
print(img_exp_2.shape, img_exp_2.dtype)
print(img_exp_3.shape, img_exp_3.dtype)
# pure noise! uniform [0..1]
img_noise = np.random.rand(img_exp_1.shape[0], img_exp_1.shape[1])
plot_image(img_exp_1)
plot_image(img_noise)
print_similarity_measures(img_exp_1, img_noise)
plot_image(img_exp_3)
plot_image(img_noise)
print_similarity_measures(img_exp_3, img_noise)
(230, 320) uint8
(240, 320) uint8
(230, 320) uint8


NCC: -0.006287200297652947 NDP: 0.8397218358602418


NCC: -0.003651187369326606 NDP: 0.8156612789563865
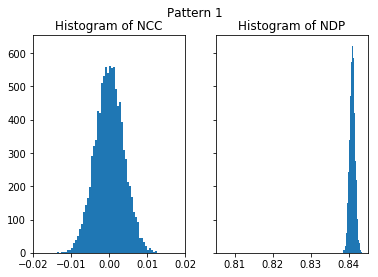
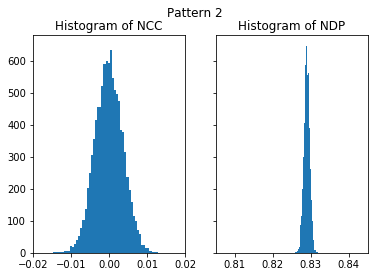
The higher NIP value of the first, higher quality, pattern (NIP=0.84) seems to indicate a better agreement with noise than the second image (NIP=0.81). It is highly counter-intuitive that extactly the same pure noise has a higher similarity to the better image, as compared to a lower similarity of the pure noise with a more noisy pattern. In contrast, the NCC is practically near 0.0 for both images, indicating that none of both image is in some way more similar to the noise.
[50]:
nruns=10000
def compare_kik_noise(nruns, img_kik, offset=0.0, scale=1.0):
""" compare Kikuchi pattern with noise
"""
nc_list=np.zeros(nruns, dtype=np.float32)
nd_list=np.zeros(nruns, dtype=np.float32)
for i in range(nruns):
# 0..1 float random numbers
img_noise = np.random.rand(img_kik.shape[0], img_kik.shape[1])
# note: difference for images 0..1 values as compared -1,1
test_kik = offset + scale * img_kik
test_noise = offset + scale * img_noise
nc_list[i] = ncc(test_kik, test_noise)
nd_list[i] = norm_dot(test_kik, test_noise)
return nc_list, nd_list
def plot_histograms(nc_vals, nd_vals, title):
fig, (ax1, ax2) = plt.subplots(1, 2, sharey=True)
ax1.hist(nc_vals, bins=50)
ax1.set_title('Histogram of NCC')
ax1.set_xlim([-0.02, 0.02])
ax2.hist(nd_vals, bins=50)
ax2.set_title('Histogram of NDP')
ax2.set_xlim([-0.02+0.825, 0.02+0.825])
plt.suptitle(title)
plt.show()
[51]:
nc_vals_1, nd_vals_1 = compare_kik_noise(nruns, img_exp_1)
plot_histograms(nc_vals_1, nd_vals_1, 'Pattern 1')
[52]:
nc_vals_2, nd_vals_2 = compare_kik_noise(nruns, img_exp_2)
plot_histograms(nc_vals_2, nd_vals_2, 'Pattern 2')
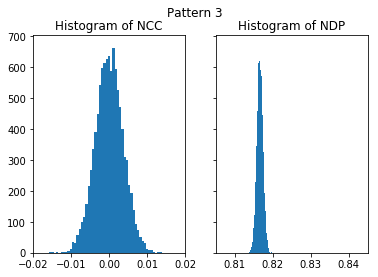
[53]:
nc_vals_3, nd_vals_3 = compare_kik_noise(nruns, img_exp_3)
plot_histograms(nc_vals_3, nd_vals_3, 'Pattern 3')
[54]:
nc_vals_4, nd_vals_4 = compare_kik_noise(nruns, img_exp_3 + 0.05*255)
plot_histograms(nc_vals_4, nd_vals_4, 'Pattern 3 + 5% Brightness')
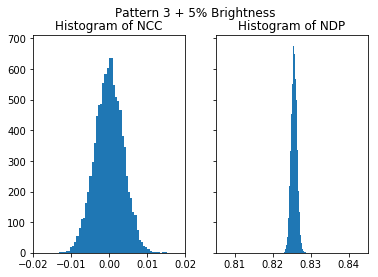
To illustrate the effect of 5% additional brightness:
[55]:
#original pattern data
plot_image(img_exp_3, limits=[0,255])

[56]:
# pattern gray levels upshifted by 5%
plot_image(img_exp_3 + 0.05*255, limits=[0,255])

Summary: Similarity Measure¶
The NCC is stable under changes of brightness and contrast, the NIP shows properties which can make its use highly unreliable for a comparison of patterns which have been obtained under varying conditions.
Equivalence of FFT convolution and Normalized Cross Correlation Coefficient¶
principle: the signals must be periodic and thus only shifted in the “unit cell”, i.e. sine or cosine must be cut at exactly the same places and padded with zeros
[57]:
kiku_exp = imread("../data/patterns/Ni_Example3.png")
kiku_exp = kiku_exp - np.nanmean(kiku_exp)
plot_image(kiku_exp)
motif_h, motif_w = kiku_exp.shape
kiku_exp.shape

[57]:
(230, 320)
For comparison, we load a simulated pattern. To take into account that we do not know the absolute scale of experiment relative to the theory, we scale the theory by an arbitrary factor.
Because we subtract the mean from the experiment and the simulation, we now have now two signals, which vary around a mean value of zero.
[58]:
kiku_sim = 137.314 * (imread("../data/patterns/Ni_Example3_sim.png", asgray=True)[:,:,0]).astype(np.float32)
kiku_sim = kiku_sim - np.nanmean(kiku_sim)
plot_image(kiku_sim)
kiku_sim.shape

[58]:
(230, 320)
For reference, we calculate the Pearson normalized cross correlation coefficient, like defined at the top of the notebook:
[59]:
r_ncc = ncc(kiku_exp, kiku_sim)
print(r_ncc)
0.5401485802133111
[60]:
def fill_fft_cell(image, shift, cell_size=512):
cell = np.zeros((cell_size, cell_size), dtype=np.float32)
shift_row = shift[0] % cell_size
shift_col = shift[1] % cell_size
for r in range(shift_row, shift_row + image.shape[0]):
for c in range(shift_col, shift_col + image.shape[1]):
cell[r % cell_size, c % cell_size] = image[r-shift_row, c-shift_col]
return cell
[61]:
reference = fill_fft_cell(kiku_exp, [0, 0])
plot_image(reference)

[62]:
# note that this works also for "backfolding" images! FFT periodicity!
shift_row = np.random.randint(0, 512)
shift_col = np.random.randint(0, 512)
print("known shift of simulation (row, col): ", shift_row, shift_col)
shifted_sim = fill_fft_cell(kiku_sim, [shift_row, shift_col])
plot_image(shifted_sim)
known shift of simulation (row, col): 271 454

[63]:
image1 = reference
image2 = shifted_sim
M, N = image1.shape
# fftshift puts the zero frequencies to the middle of the array
xc_fft = np.fft.fftshift(np.abs( np.fft.ifft2( np.fft.fft2(image1) * np.fft.fft2(image2).conjugate()) ))
plot_image(xc_fft)
f, ax = plt.subplots(figsize=(5, 5))
ax.imshow(np.flipud(np.fliplr(xc_fft)), cmap='plasma',
extent=(-N // 2, +N // 2, M // 2, -M // 2))
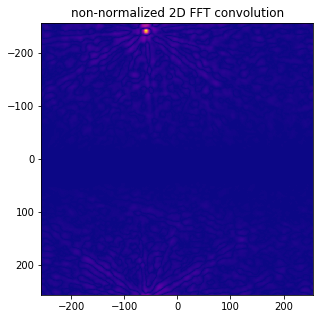
ax.set_title('non-normalized 2D FFT convolution');
max_xcfft = np.unravel_index(np.argmax(xc_fft, axis=None), xc_fft.shape)
row_max = (256 - max_xcfft[0]) % 512
col_max = (256 - max_xcfft[1]) % 512
print ('position of maximum ( rows, cols, [0,0] at center, fftshift): ', row_max, col_max)
print ('xc fft max', np.max(xc_fft))

position of maximum ( rows, cols, [0,0] at center, fftshift): 271 454
xc fft max 7820401700.0
[64]:
autocorrelation_1 = np.fft.fftshift(np.abs(np.fft.ifft2(np.fft.fftn(image1)*np.fft.fft2(image1).conjugate())))
autocorrelation_2 = np.fft.fftshift(np.abs(np.fft.ifft2(np.fft.fftn(image2)*np.fft.fft2(image2).conjugate())))
plot_image(np.log(autocorrelation_1+0.1), title='log(autocorrelation) image 1', cmap='viridis')
plot_image(np.log(autocorrelation_2+0.1), title='log(autocorrelation) image 2', cmap='viridis')
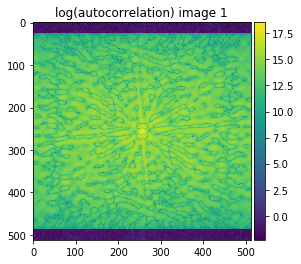
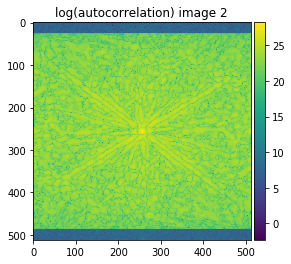
[65]:
intensity_1 = np.max(autocorrelation_1)
intensity_2 = np.max(autocorrelation_2)
xc_denom = np.sqrt(intensity_1)* np.sqrt(intensity_2)
xc_normalized = xc_fft/xc_denom
f, ax = plt.subplots(figsize=(4.8, 4.8))
# set extent to have axes with shift value (0,0) at center and shifting corresponding visually to images
# (only ++ quadrant is used for the known shift)
ax.imshow(np.flipud(np.fliplr(xc_normalized)), cmap='plasma',
extent=(-N // 2, N // 2, M // 2, -M // 2))
ax.set_title('normalized XC FFT');
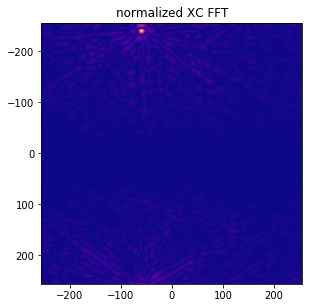
We can now find the position of the maximum and the corresponding value of xc_normalied, which should correspond to the cross correlation coefficient reference value r_ncc as calculated above:
[66]:
# indices of maxmimum in 2D
max_rc = np.unravel_index(np.argmax(xc_normalized, axis=None), xc_normalized.shape)
# maximum value shoould be at theoretical shift vector
r_fft = np.max(xc_normalized)
print('Compare results (should be equal):\n')
print('known shift vector: ', shift_row, shift_col)
print('position of found r_fft maximum: ', (256 - max_rc[0]) % 512 , (256 - max_rc[1]) % 512)
print('r_fft: ', r_fft)
print('r_ncc: ', r_ncc)
# throw error if not equal up to 6 decimals
np.testing.assert_almost_equal(r_fft, r_ncc, 6)
Compare results (should be equal):
known shift vector: 271 454
position of found r_fft maximum: 271 454
r_fft: 0.54014856
r_ncc: 0.5401485802133111
We have thus shown how to obtain the same cross-correlation coefficient as r_ncc by (a) normalization (mean=0, stddev=1.0) of the input images and then padding by zeroes inside a common 2D array size, and (b) the suitable scaling of the FFT by the maximum of the autocorrelations of both images (i.e. the energy in both images). This demonstrates the intrinsic similarity of r_fft (determined by FFT) and r_ncc (determined by pixel-wise formula for the normalized cross-correlation coeffcient).
Subpixel resolution¶
http://scikit-image.org/docs/dev/auto_examples/transform/plot_register_translation.html
[67]:
from skimage import data
from skimage.feature import register_translation
from skimage.feature.register_translation import _upsampled_dft
from scipy.ndimage import fourier_shift
image = image1
shift = (12.4, 3.32)
# The shift corresponds to the pixel offset relative to the reference image
offset_image = fourier_shift(np.fft.fft2(image), shift)
offset_image = np.fft.ifft2(offset_image)
print("Known offset (y, x): {}".format(shift))
# pixel precision first
shift, error, diffphase = register_translation(image, offset_image)
print("Detected pixel offset (y, x): {}".format(shift))
fig = plt.figure(figsize=(8, 3))
ax1 = plt.subplot(1, 3, 1)
ax2 = plt.subplot(1, 3, 2, sharex=ax1, sharey=ax1)
ax3 = plt.subplot(1, 3, 3)
ax1.imshow(image, cmap='gray')
ax1.set_axis_off()
ax1.set_title('Reference image')
ax2.imshow(offset_image.real, cmap='gray')
ax2.set_axis_off()
ax2.set_title('Offset image')
# Show the output of a cross-correlation to show what the algorithm is
# doing behind the scenes
image_product = np.fft.fft2(image) * np.fft.fft2(offset_image).conj()
cc_image = np.fft.fftshift(np.fft.ifft2(image_product))
ax3.imshow(cc_image.real)
#ax3.set_axis_off()
ax3.set_title("Cross-correlation")
plt.show()
# subpixel precision
shift, error, diffphase = register_translation(image, offset_image, 200)
fig = plt.figure(figsize=(8, 3))
ax1 = plt.subplot(1, 3, 1)
ax2 = plt.subplot(1, 3, 2, sharex=ax1, sharey=ax1)
ax3 = plt.subplot(1, 3, 3)
ax1.imshow(image, cmap='gray')
ax1.set_axis_off()
ax1.set_title('Reference image')
ax2.imshow(offset_image.real, cmap='gray')
ax2.set_axis_off()
ax2.set_title('Offset image')
# Calculate the upsampled DFT, again to show what the algorithm is doing
# behind the scenes. Constants correspond to calculated values in routine.
# See source code for details.
cc_image = _upsampled_dft(image_product, 150, 100, (shift*100)+75).conj()
ax3.imshow(cc_image.real)
ax3.set_axis_off()
ax3.set_title("Supersampled XC sub-area")
plt.show()
print("Detected subpixel offset (y, x): {}".format(shift))
Known offset (y, x): (12.4, 3.32)
Detected pixel offset (y, x): [-12. -3.]


Detected subpixel offset (y, x): [-12.4 -3.32]
Appendix¶
Numpy corrcoef¶
We can also use numpy directly to get the NCCs for all combinations of several data sets In the returned matrix of numpy.corrcoef, the i-j element gives the NCC of dataset i with dataset j.
For an example, see also: https://stackoverflow.com/questions/3425439/why-does-corrcoef-return-a-matrix
[68]:
datasets=[U_true,U_exp,V_true,V_exp]
ncc_matrix=np.corrcoef(datasets)
print(ncc_matrix)
[[1. 0.5954721 1. 0.91582973]
[0.5954721 1. 0.5954721 0.58435245]
[1. 0.5954721 1. 0.91582973]
[0.91582973 0.58435245 0.91582973 1. ]]